자연어처리(NLU)를 하기 위한 소프트웨어 아키텍쳐 - 걸음마단계부터 인간 수준으로 진화하는 방향에 대해 알아본다 | |||
 422 422  0 0  0 0  0 0 | |||
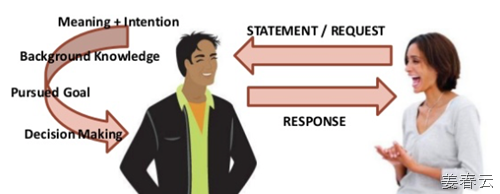
| 자연어 처리의 역사는 1950년대로 거슬러 올라가야 합니다. 당시 지금과 같은 컴퓨터 기술이 없었을때도 로봇이 사람의 말을 알아들을 수 있을까에 대한 의구심이 있었습니다. 또한 어떻게 하면 로봇이 사람의 말을 인지할 수 있을까에 대한 궁금증 또한 있었습니다. 인공지능의 가장 큰 도전과제는 어떻게 지식을 이해하고 표현할 것인가일 것입니다. 이해하는 것과 표현하는 것은 다를 것 같지만, 결국 그 둘의 공통분모는 이를 어떻게 정보화 할 것이냐에 대한 결과로 도출이 됩니다. 자연어처리라는 학문은 NLU라고 부르며 Natural Language Understanding의 줄임말입니다. 즉, 자연어에 대한 이해… 우리가 사용하는 언어는 일련의 규칙을 가지고 있으며, 여러가지 상황이 얽혀 있습니다. 소프트웨어 측면에서는 Multiple Query의 조합(Combination)이라고 할 수 있으며, 이는 어떠한 상황(State)에 대한 정보도 포함합니다. 이를 흐름도로 도식화 하면 다음과 같이 나타 낼 수 있습니다.
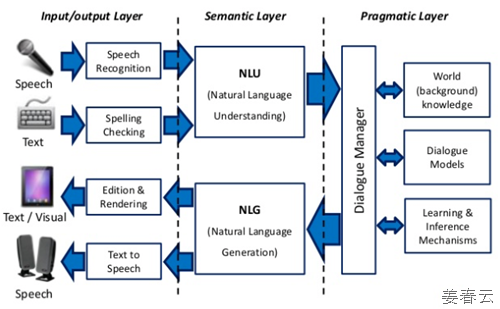
우리가 어떠한 사실이나 개체를 인지할때는 대화를 통해서 알게 됩니다. 이것이 축적되면 굳이 대화를 나누지 않아도 우리 머리속에 그러한 상황정보가 남게 되고, 굳이 여러 대화를 나누지 않아도 한방에 알 수 있게 되는 것입니다. 결국 우리가 자연어처리 시스템을 구축한다고 하면 결국 “대화형 시스템”을 구축한다라고… 말해야 하는 것이 맞습니다. 대화형 시스템의 3단계 레이어를 도식화 하면 다음과 같이 나타 낼 수 있습니다.
위의 그림에서 Dialogue Manager에서 핵심적인 기능은 있는 정보를 오케스트레이션(잘 버무리는 것; Dialog Orchestration)입니다. 이를 가능하게 하려면 양질의 메타데이터와 그에 따른 빅데이터가 있어야 가능할 것입니다.
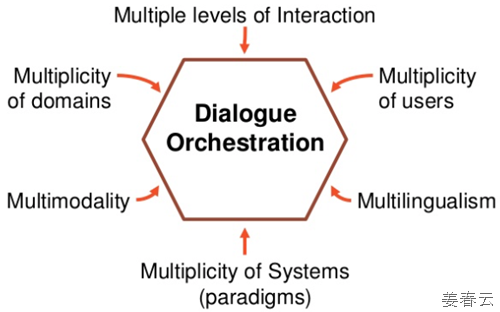
대화 시 상황정보를 받아들이는 계층을 도식화 하면 다음과 같이 표현 할 수 있습니다. 소프트웨어적 측면에서는 다음의 4단계로 나눌 수 있습니다.
지금까지 구현된 대화형 솔루션은 3번까지입니다. 4번의 경우 일부 업체들이 그러한 기술을 구현했고, 계속 발전하고 있는 상태입니다. 대화형 솔루션의 궁극의 목표는 누가 말했느냐… 까지 구현하는 것일 것입니다.
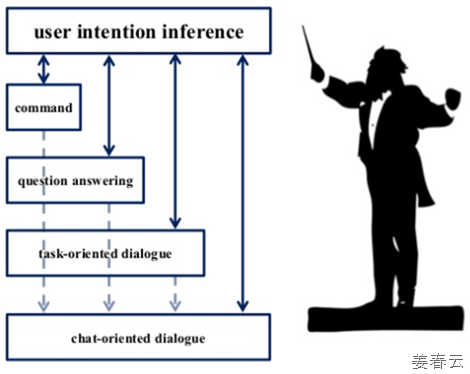
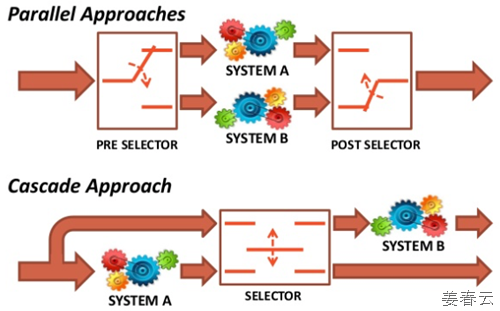
이러한 정보를 효과적으로 오케스트레이션하는 방법론으로는 다음과 같은 접근이 가능할 것입니다.
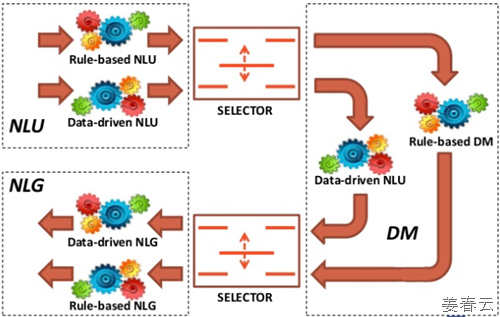
마지막으로 자연어 처리는 Rule-based DM(Dialog Management) 또는 Data-based DM(Dialog Management)를 기반으로 동작하게 될 것입니다.
현실적으로 자연어처리 소프트웨어를 만든다면 “자연어 처리로 무엇을 할 것이냐”에 대한 답을 가지고 있어야 가능 할 것입니다. 예를 들면 다음과 같은 목표가 있어야 합니다.
아마도 가까운 미래에는 위와 같은 DM Engine이 많이 만들어져 있을 것이고, 이것을 다시 오케스트레이션 하는 통합 엔진이 나올 것입니다. 그러면 정말 인간과 가까와지는 천재 로봇이 나올지도 모르겠군요. Tags: Chat Command Dialog Orchestration NLU Natural Language Understanding Query Question Task 검색 대화형 대화형 솔루션 상황정보 아키텍쳐 오케스트레이션 자연어처리 질문 추천 알고리즘 할 일 홈쇼핑 | |||
| |||
| |||
| Login for comment |

 31437
31437