집단지성을 활용하는 Collaborative Filtering(CF) 알고리즘 - 추천 알고리즘으로 많이 이용되고 있지만, 한계도 알아야 해 | |||
 432 432  0 0  0 0  0 0 | |||
| 오늘은 Collaborative Filtering에 대해 간단히 정리해보려고 합니다. 업무상 이와 관련된 내용을 자주 접하지만, 어딘가 정리를 해서 놓을 필요가 있다는 생각이 들어 블로그에 올려봅니다. 참고로 이는 전혀 새로운 알고리즘이나 방법이 아니며, 이미 학술적으로도… 또한 업계에서도 널리 응용되고 있는 방법입니다. 본 포스트에서는 Collaborative Filtering에 대해 그 정의와 응용(Application)에 대해 간단히 소개하고자 합니다.
1. Collaborative filtering이란? Collaborative filtering (CF; 이하는 CF로 줄여서 표기)은 추천 시스템에서 사용하는 기법 중 하나입니다.
CF는 여러 에이젼트, 뷰포인트, 데이터 소스와의 협업(콜레보레이션; Collaboration)을 포함하는 기술을 사용하여 정보 또는 패턴을 필터링하는 프로세스입니다. 뉴스나 드라마에서 콜라보(Collaboration의 줄임말)를 했다는 말을 종종 들으셨을 것입니다. 콜라보란 협업(Collaboration)을 했다는 의미인데, 이를 바탕으로 CF를 다시 정의하면, 사전적으로는 여러 소스를 참조하여 불필요한 정보를 차단한다는 의미인데, 다르게 해석하면 관심 있어할 정보만 찾아준다는 것으로 풀이할 수 있습니다.
CF 알고리즘은 빅데이터(Big-Data)를 기반으로 처리되는데, 다음과 같은 분야에 널리 이용되고 있습니다.
알고리즘 측면에서 CF를 다시 정의하면 CF는 다양한 사용자의 선호도를 수집하여 사용자의 관심 분야를 자동으로 예측하도록 하는 방법입니다. CF의 가장 흔한 접근 방법은 “당신이 구입한 제품을 구입한 다른 고객은 A라는 제품에도 관심을 보이셨습니다.”라는 방식의 접근입니다. 다른 사례로는 “명량”이라는 영화를 본 사람이 있다고 하면, 이 사람에게 “명량을 보신 고객분들 중 많은 분들이 해적도 보셨습니다”라고 추천을 해주는 것을 예로 들을 수 있습니다. 이는 서비스를 운영하는 사람의 관점에 있어서는 2차 구매를 유도하여 또 다른 수익을 내는 기회를 만들어낼 수 있다는 장점이 있습니다. 이러한 처리 기법은 아마존(Amazon)이나 알리바바(Alibaba) 같은 쇼핑몰은 물론 넷플릭스(Netflix)같은 VOD 서비스 업체에도 적용이 된 바 있습니다.
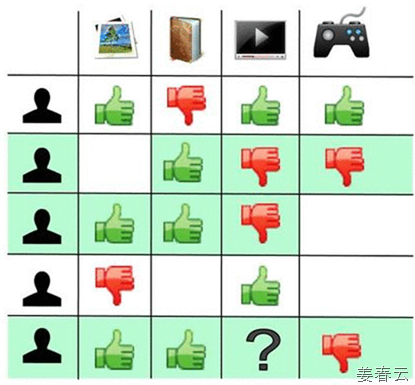
2. CF 방법론(Methodology) 1) User-based CF : 일반적으로 가장 많이 이용되는 방법으로 Nearest Neighbor Algorithm이라고도 불리우며 그 처리 프로세스는 다음과 같습니다.
아래의 사례가 본 사례와 유사한 것 같습니다.
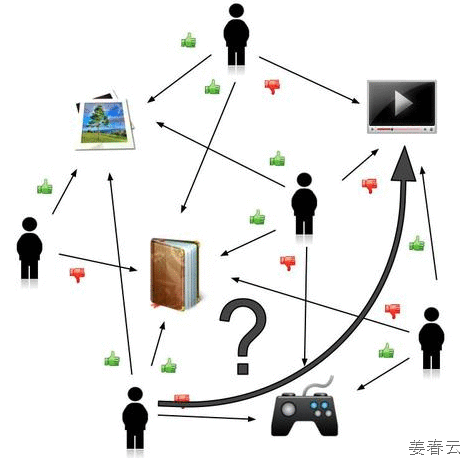
2) Item-based CF : 아마존(Amazon)이 이를 처음으로 사용한 것으로 알려져 있으며, 통상 “users who bought x also bought y”라는 형태로 많이 알려져 있습니다. 이 방식에 대한 처리 프로세스는 다음과 같습니다.
하나 주시해야 할 점은 별점(등급) 방식은 모든 사용자를 만족시키는 것이 아니라 평균적인 대중의 의견을 반영하는 것이므로 선호도나 관심도가 다양한 분야에 적용 시, 그 결과가 만족스럽지 않을 수 있습니다. 이런 경우 검색(Search)이나 Data Clustering같은 방법을 이용하는 편이 좋은 결과로 이어지는 경우가 많습니다.
3. CF 구현 방식 CF 구현방식에는 Memory-based CF, Model-based CF, Hybrid CF의 3가지 방식이 있습니다. CF 알고리즘을 적용하려고 계획하고 있다면, 그 용도와 Data Source의 Size에 대해 충분히 고민한 후 구현 방식을 정하는 것이 적절하다 판단됩니다.
1) Memory-based CF Memory-based CF는 사용자의 선호도(Rating) 기반으로 사용자(User) 또는 아이템(Item)의 유사도를 계산하는 방법을 이용하는 것으로, 추천 솔루션 개발에 널리 이용됩니다. 쇼핑몰이나 VOD 서비스에서 제공하는 대다수의 추천 기술은 이 방식으로 서비스 되고 있습니다. 위에 기술했습니다만, Nearest Neighbor Algorithm이 널리 이용되고 있으며 아이템(Item)/사용자(User) 기반 top-N 추천 알고리즘 또한 널리 이용되고 있습니다. 이 방식의 단점은 다음과 같습니다.
2) Model-based CF 이는 Usage 데이터를 기반으로 Training을 하여 패턴을 발견하는 과학적인 기법입니다. 이는 보통 실제 Data에 대한 예측을 하는데 이용되는데, 일기예보 등이 이에 해당합니다. 여기에는 베이지안, 클러스터링, 시맨틱 등 수학적 모델을 기반으로 추천을 하는 다양한 알고리즘이 존재합니다. Model-based CF는 Memory-based에 비해 적은 소스 모수를 사용하고 데이터가 크면 클수록 예측 퍼포먼스가 좋아 진다는 장점이 있으며, 반대로 모델을 만드는데 비용이 많이 소요되고, 데이터가 크면 클수록 퍼포먼스가 떨어진다는 단점이 있습니다.
3) Hybrid CF 당연한 예측 결과겠지만, Memory-based CF와 Model-based CF를 혼용하면 적은 모수의 소스에 대해서도 대응이 가능하다는 장점이 있으나, 이에 따라 비용이 증가하고 구현 복잡도도 높아진다는 단점이 있습니다. 예를 들어 Google의 뉴스 추천 서비스가 이에 해당합니다.
4. CF의 문제점 1) 정확도 추천 시스템을 만드는 많은 과학자들이 “그래서 추천 정확도가 높아졌어?”라는 질문을 받습니다. CF만 가지고 개인화 추천의 선호도를 모두 맞추는 것은 불가능합니다, 다만 대중의 의견을 반영하였으므로 대개는 맞아떨어진다고 하는 것이 맞습니다. 2) 콜드스타트(Cold Start) CF는 수집된 패턴을 근간으로 움직이므로, 새로운 사용자나 새로운 아이템이 등장했을 경우 사용 데이터 부족으로 인하여, 적절하게 추천되지 않을 가능성이 높습니다. 이런 경우라면 새로운 사용자의 경우에는 좋아하는 영화, 좋아하는 음식, 장르 등… 선호도를 미리 기초 데이터로 받아야 할 것이고, 새로운 아이템이 등장했을 경우에는 이것이 필요한 사람들에게 의도적으로 노출되게 하는 UI(User Interface)적 접근이 필요 할 것입니다.
5. CF 알고리즘 적용 시 고려 사항 CF를 구현함에 있어, CF의 성능에 방해가 되는 여러 요인들이 있습니다. 하여 CF 구현 시 아래의 항목에 대한 대응 전략이 있는지… 미리 검토/고민 할 필요가 있습니다. 1) 소스 데이터의 분량(Data Sparsity) 2) 확장성(Scalability) 3) 유사품(Synonyms)에 대한 처리 정책 4) 검색봇(bot) 등 추천에 방해되는 인자(Grey sheep)에 대한 예외 처리 정책 5) 일부러 남의 경쟁자의 아이템에 대해 부정적인 Voting을 하고, 자기 아이템에 대해 긍정적인 Voting을 하는 Shilling attacks에 대한 대응 방안 6) 오래된 아이템(Long Tail)에 대한 Rating이 높아 새로운 아이템이 추천되지 못할 가능성에 대한 대응 방안: 신규 아이템은 별도 노출을 해주는 UI 구성 등.
이상 CF(Collaborative Filtering)에 대해 알아보았습니다.
Tags: 1998년 Alibaba Amazon Big-Data Collaboration Collaborative Filtering Data Clustering Data Sparsity Grey sheep Hybrid CF Item-based CF Memory-based CF Methodology Model-based CF Nearest Neighbor Algorithm Netflix Prediction Rating Scalability Search Shilling attacks Synonyms User-based CF 검색봇 넷플릭스 빅데이터 수학적 모델 아마존 아키텍쳐 알리바바 유사품 정확도 집단지성 추천 추천 알고리즘 추천 정확도 콜드스타트 콜라보 콜레보레이션 필터링 확장성 | |||
| |||
| |||
| 로그인을 하시면 댓글을 등록 할 수 있습니다. |

 31399
31399